

Achieving Rapid CCPA Compliance with GenAI-Powered Analysis
Problem Statement
The client's expert legal team could meticulously analyze a handful of policies per day. Faced with a deluge of over 5,000 complex legal documents, their existing workflow was operationally and financially unviable. To meet the deadline manually, it would have required hiring an army of legal analysts, delaying their market response by months and erasing their profit margins. They had hit a scalability wall that their human resources couldn't break through.
Client Info
A trusted, established name in online privacy protection with large user base. Their brand is built on accuracy and reliability, and their customers depend on them to navigate the complex, ever-changing landscape of data privacy regulations.
Outcomes
10x faster compliance analysis
60% Cost-effective scaling of privacy operations
How did BeautifulCode do it?
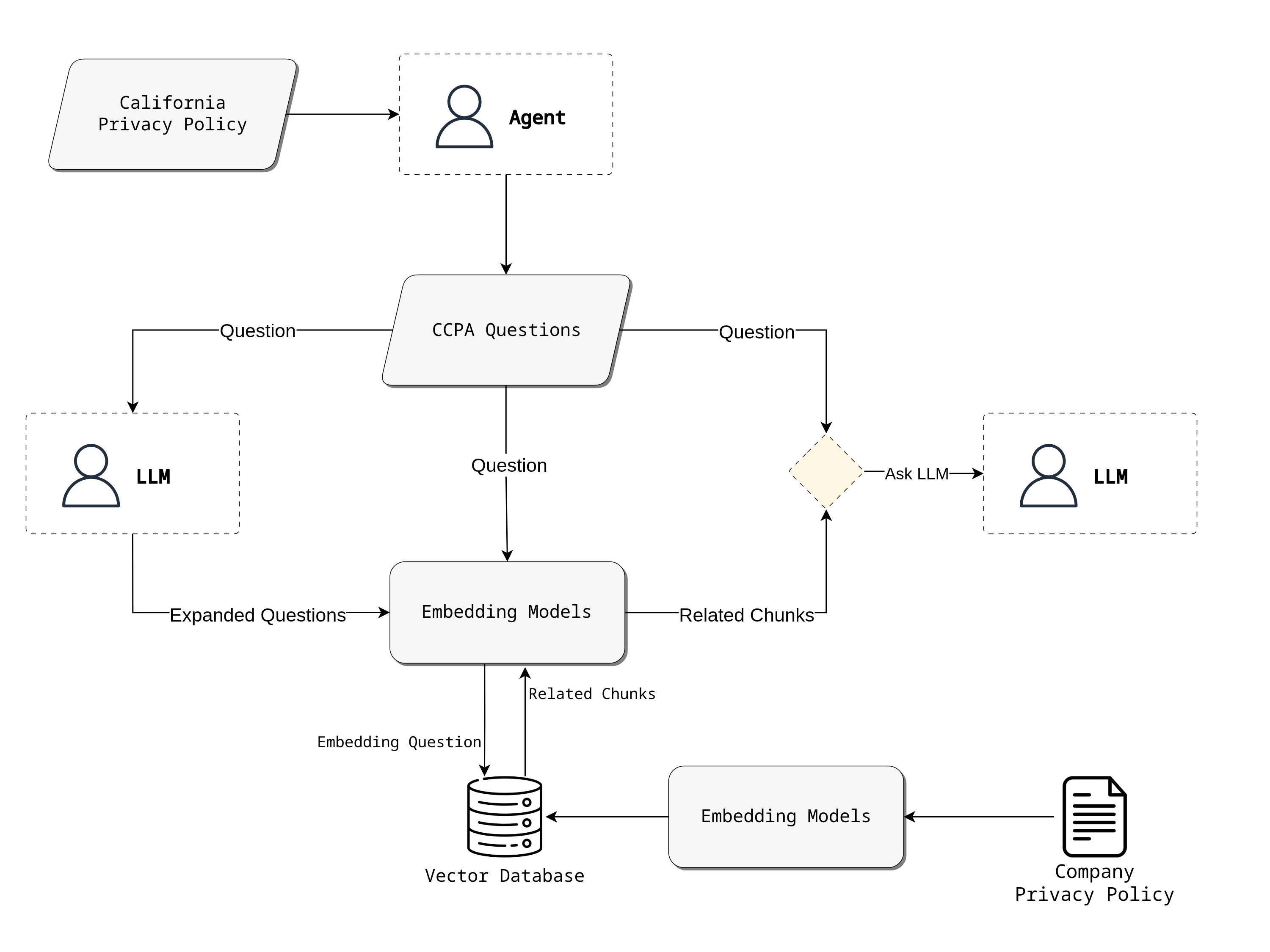
BeautifulCode first invested time to understand the manual workflow and pinpoint the primary bottleneck: the time-consuming and tedious process of having legal experts read and interpret thousands of lengthy, complex privacy policies. To overcome this, we designed and implemented a sophisticated analysis pipeline powered by Large Language Models (LLMs).
Our approach automated the discovery and assessment process through a series of carefully orchestrated steps:
Building the Knowledge Base (RAG Pipeline)
We initiated a Retrieval-Augmented Generation (RAG) pipeline to process the vast number of privacy policies. Each policy was systematically broken down into smaller, digestible chunks. These chunks were then converted into numerical representations (embeddings) and stored in a specialized vector database, creating a searchable library of policy information.
Generating Targeted Questions
Instead of manual interpretation, we used the official CCPA compliance policy as a source document. We prompted an LLM to act as a legal expert and generate a precise set of questions based on the new, nuanced definition of "selling consumer data."
Expanding the Scope of Inquiry
To ensure a comprehensive analysis and avoid missing relevant policy clauses, we used an LLM to expand upon each generated question. This created multiple variations and phrasings, covering a wider range of potential legal jargon and terminology.
Intelligent Information Retrieval
For each of the 5,000+ companies, our system iterated through the expanded questions. It queried the vector database to find the most relevant chunks from each company's privacy policy, using metadata filters to ensure accuracy.
AI-Powered Analysis and Confidence Scoring
The retrieved policy chunks and the original question were fed into a final LLM. This model was tasked with making a determination: was the company selling data as per the CCPA rules? The output was a confidence score indicating the certainty of its assessment. All results with low confidence were automatically flagged and escalated for an efficient human review, ensuring accuracy without sacrificing speed.
Technologies Used
© 2025 BeautifulCode. All rights reserved.