

Dispruting Upskilling with GenAI
Problem Statement
The client's growth was creating a critical training bottleneck. With a constant influx of new hires, their traditional mentor-led model couldn't scale. Each experienced mentor could only support a handful of mentees, leading to long wait times, delayed project readiness, and missed revenue opportunities. They needed a way to break the linear relationship between mentors and mentees to unlock scalable growth.
Client Info
A global systems integrator with over 50,000 employees. Their business model relies on hiring thousands of university graduates each year and rapidly deploying them to billable client projects.
Outcomes
(5x) Scaling of mentees for a given mentor
Halfed the training time of ramping up of leaners into projects
Achieved a 95% course completion rate by eliminating feedback delays and keeping learners engaged.
How did BeautifulCode do it?
BeautifulCode began by analyzing the critical pain points in the client's traditional training model. The process was heavily reliant on mentor availability, leading to bottlenecks in feedback, inconsistent evaluation, and a significant time lag between learning and application. This model was not scalable and struggled to provide the deep, personalized assessment needed to ensure learners were truly project-ready. To solve this, we developed an intelligent, multi-stage upskilling platform powered by Generative AI. The new process creates a structured, interactive, and highly efficient learning journey:
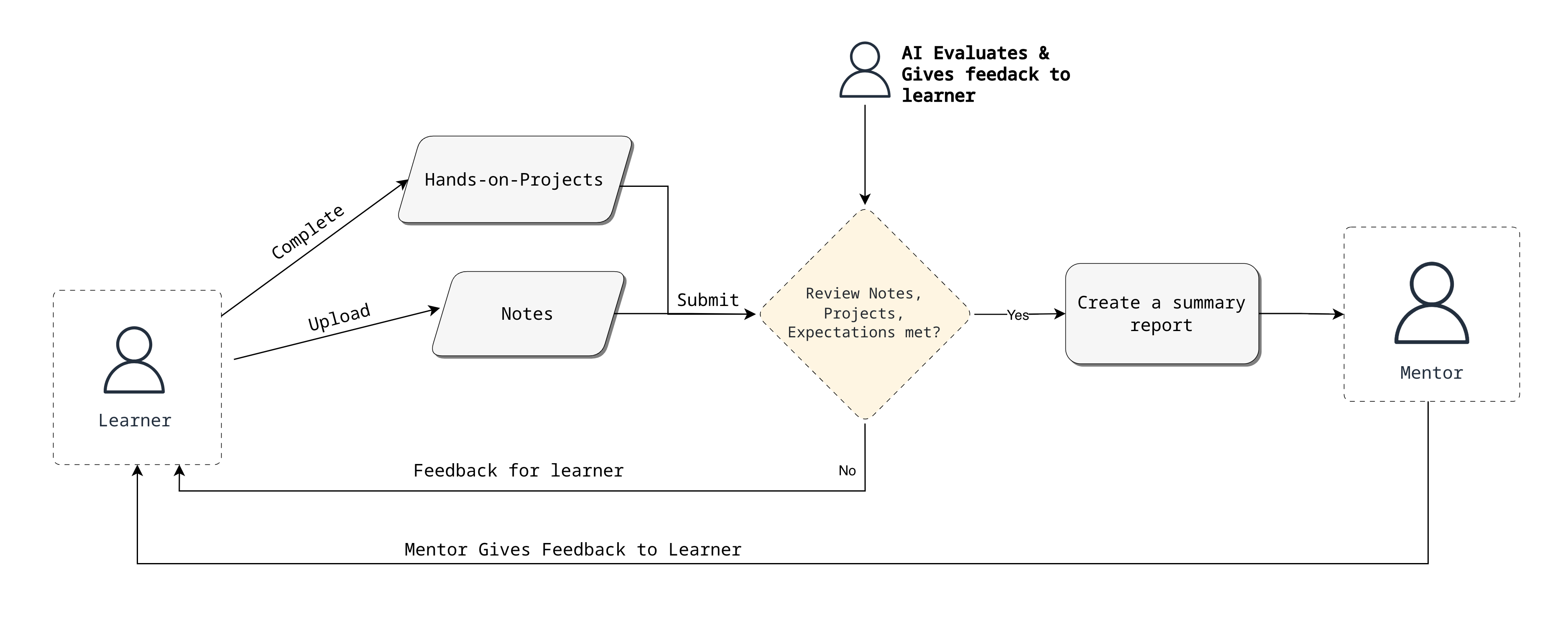
To solve this, we developed an intelligent, multi-stage upskilling platform powered by Generative AI. The new process creates a structured, interactive, and highly efficient learning journey:
Structured Course Design
The process begins with the course designer, who curates modules and learning tasks. Crucially, for each task, they embed the specific concepts a learner is expected to grasp and formulate targeted questions to validate that understanding. This creates a clear framework for both teaching and assessment.
Learner-Centric Input
After completing the learning tasks, the learner digitizes and uploads their handwritten notes into the system. This step is designed to capture their authentic thought process and initial understanding of the material.
AI-Powered Note Analysis
The platform's AI analyzes these notes to check for comprehension of the key concepts defined by the course designer. It provides immediate, constructive feedback to the learner, pinpointing areas of misunderstanding or gaps in their knowledge.
Adaptive Assessment and Mentor Reporting
If the AI determines the notes sufficiently cover the required concepts, the module is marked as complete. However, if key concepts are missing, the AI initiates a dialogue, asking the specific questions the course designer had prepared. It assesses the learner's responses, provides further feedback to solidify their understanding, and only then marks the module as complete. Upon completion, the AI generates a concise summary report for the mentor, detailing the learner's performance.
Seamless Mentor Handoff
Once a learner completes all modules, the mentor has access to a comprehensive overview of their entire learning journey. This allows mentors to bypass granular, repetitive checks and focus their time on high-impact, strategic conversations, preparing the learner for the final project phase.
Rigorous Evaluation Framework
To ensure the AI-generated feedback matched the quality and effectiveness of human mentors, we established a comprehensive evaluation system. We created a golden dataset of authentic human mentor feedback, which served as our quality benchmark. Using LangSmith, we implemented an LLM-as-judge evaluation framework that systematically assessed the AI's output against these gold-standard examples from experienced mentors.
This evaluation system became the gatekeeper for all changes to production. Every prompt modification underwent rigorous testing against our benchmark dataset. We only promoted changes to production if they maintained an average pass percentage within a strict 5% tolerance of our baseline. This disciplined approach ensured that improvements in one area never came at the cost of regression in feedback quality or mentoring tone.
Fine-Tuning for Feedback Quality and Cost Efficiency
Achieving the right balance of feedback strictness and mentoring tone proved challenging with standard prompting techniques. Initial attempts using prompt engineering and few-shot examples failed to consistently replicate the nuanced feedback style that experienced mentors provided. To address this, we curated a dataset of 100 authentic feedback examples from human mentors, capturing their evaluation approach and communication style. We fine-tuned a GPT-4o model on this dataset, which successfully achieved the targeted strictness and tone in its feedback.
To optimize operational costs while maintaining quality, we implemented a cascading fine-tuning strategy. We generated 500 high-quality feedback examples using the fine-tuned GPT-4o model and used this synthetic dataset to fine-tune a GPT-4o-mini model. This cost-efficient mini model, trained on outputs from its larger counterpart, now powers the production system—delivering mentor-quality feedback at a fraction of the computational cost.
Technologies Used
© 2025 BeautifulCode. All rights reserved.